DataFrame Aggregation adalah proses menghitung nilai agregat dari seluruh baris atau kolom pada dataframe. Nilai agregat yang umum digunakan adalah:
- Mean: rata-rata dari seluruh nilai pada kolom.
- Median: nilai tengah dari seluruh nilai pada kolom, setelah nilai tersebut diurutkan.
- Mode: nilai yang paling sering muncul pada kolom.
- Min: nilai terkecil pada kolom.
- Max: nilai terbesar pada kolom.
- Sum: jumlah seluruh nilai pada kolom.
- Count: jumlah seluruh nilai pada kolom (termasuk nilai null).
DataFrame Aggregation sering dilakukan dalam proses data analysis untuk mengetahui karakteristik data secara keseluruhan.

Misalnya, kamu dapat menggunakan DataFrame Aggregation untuk menjawab pertanyaan-pertanyaan seperti:
- Berapa rata-rata usia pada dataframe?
- Berapa median gaji pada dataframe?
- Berapa nilai minimum dan maksimum dari kolom “Usia”?
- Berapa total jumlah nilai pada kolom “Gaji”?
Dataframe yang digunakan pada artikel kali ini adalah
Nama Age Gaji Pendidikan
0 Andi 21 1000 S1
1 Budi 22 2000 S1
2 Caca 23 3000 S2
3 Deni 24 4000 S2
4 Euis 25 5000 S3
Menampilkan Statistik dengan Fungsi Describe
Di Pandas, kamu dapat menggunakan fungsi describe() atau metode agg() untuk menghitung nilai agregat pada dataframe.
Fungsi describe() akan menghitung berbagai statistik agregat secara cepat, seperti mean, min, max, dan lain-lain pada setiap kolom numerik pada dataframe.
Berikut ini adalah contoh kode untuk menghitung statistik agregat menggunakan fungsi describe():
import pandas as pd
# Membaca data dari file CSV
df = pd.read_csv('data.csv')
# Menghitung statistik agregat pada dataframe
statistics = df.describe()
print(statistics)Sedangkan metode agg() memberikan fleksibilitas yang lebih tinggi dalam menghitung nilai agregat, karena kamu dapat menentukan sendiri fungsi agregat yang ingin dihitung atau menggunakan fungsi agregat yang didefinisikan sendiri atau dari library lain.
Berikut ini adalah contoh kode untuk menghitung nilai agregat menggunakan metode agg():
# Menghitung rata-rata usia pada dataframe
mean_age = df['Usia'].mean()
print(mean_age)
# Menghitung median usia pada dataframe
median_age = df['Usia'].median()
print(median_age)GroupBy Function
GroupBy Function adalah fungsi yang digunakan untuk membagi dataframe menjadi beberapa kelompok berdasarkan kriteria tertentu.
Setelah dataframe terbagi menjadi beberapa kelompok, kamu dapat menghitung nilai agregat pada setiap kelompok secara terpisah menggunakan fungsi agregat seperti mean, median, min, max, dan lain-lain.
Untuk menggunakan GroupBy Function pada dataframe, kamu dapat menggunakan metode groupby() pada dataframe, kemudian menentukan kolom yang akan digunakan sebagai kriteria pembagian dataframe.
Berikut ini adalah contoh kode untuk menggunakan GroupBy Function pada dataframe:
# Membagi dataframe menjadi beberapa kelompok berdasarkan kolom "Jenis Kelamin"
grouped_df = df.groupby('Jenis Kelamin')
# Menghitung nilai agregat pada setiap kelompok menggunakan metode agg()
aggregates = grouped_df.agg(['mean', 'median', 'min', 'max'])
print(aggregates)
Di sini, kita membagi dataframe menjadi dua kelompok berdasarkan kolom “Jenis Kelamin”, kemudian menghitung nilai agregat pada setiap kelompok menggunakan metode agg().
Kamu dapat menambah atau mengurangi fungsi agregat sesuai dengan kebutuhan kamu pada parameter list tersebut.

GroupBy Function sangat bermanfaat untuk memahami karakteristik data pada setiap kelompok secara terpisah dan membuat keputusan berdasarkan data yang tersedia.
Misalnya, kamu dapat menggunakan GroupBy Function untuk menjawab pertanyaan-pertanyaan seperti:
- Berapa rata-rata usia pada setiap kelompok berdasarkan jenis kelamin?
- Berapa median gaji pada setiap kelompok berdasarkan jenis kelamin?
- Berapa nilai minimum dan maksimum dari kolom “Usia” pada setiap kelompok berdasarkan jenis kelamin?
- Berapa total jumlah nilai pada kolom “Gaji” pada setiap kelompok berdasarkan jenis kelamin?
Dan lain-lain. GroupBy Function sangat bermanfaat untuk memahami karakteristik data pada setiap kelompok secara terpisah dan membuat keputusan berdasarkan data yang tersedia.
GroupBy Function dengan multi kolom
Selain itu, kamu juga dapat menggunakan GroupBy Function dengan beberapa kolom sekaligus sebagai kriteria pembagian dataframe. Misalnya:
# Membagi dataframe menjadi beberapa kelompok berdasarkan kolom "Jenis Kelamin" dan "Pendidikan"
grouped_df = df.groupby(['Jenis Kelamin', 'Pendidikan'])
# Menghitung nilai agregat pada setiap kelompok menggunakan metode agg()
aggregates = grouped_df.agg(['mean', 'median', 'min', 'max'])
print(aggregates)Di sini, kita membagi dataframe menjadi beberapa kelompok berdasarkan kolom “Jenis Kelamin” dan “Pendidikan”, kemudian menghitung nilai agregat pada setiap kelompok menggunakan metode agg().
kamu dapat menambah atau mengurangi fungsi agregat sesuai dengan kebutuhan kamu pada parameter list tersebut.
GroupBy Function dengan multi kolom dan multi statistik
GroupBy Function dengan multi kolom dan multi statistik juga sangat bermanfaat dalam kasus-kasus dimana kamu ingin menghitung beberapa nilai agregat pada setiap kelompok berdasarkan beberapa kriteria tertentu.
Selain itu, kamu juga dapat menggunakan GroupBy Function dengan parameter dictionary yang menyimpan pasangan nama kolom dan nama fungsi agregat, untuk menghitung nilai agregat pada kolom tertentu saja. Misalnya:
# Membagi dataframe menjadi beberapa kelompok berdasarkan kolom "Jenis Kelamin"
grouped_df = df.groupby('Jenis Kelamin')
# Menghitung nilai agregat pada kolom "Usia" dan "Gaji" menggunakan metode agg()
aggregates = grouped_df.agg({
'Usia': ['mean', 'median', 'min', 'max'],
'Gaji': ['sum', 'count']
})
print(aggregates)
Di sini, kita membagi dataframe menjadi beberapa kelompok berdasarkan kolom “Jenis Kelamin”, kemudian menghitung nilai agregat pada kolom “Usia” dan “Gaji” menggunakan metode agg().
Nilai agregat yang dihitung di sini adalah mean, median, min, max untuk kolom “Usia”, dan sum, count untuk kolom “Gaji”.
kamu dapat menambah atau mengurangi fungsi agregat sesuai dengan kebutuhan kamu pada parameter dictionary tersebut.
Setelah kamu membagi dataframe menjadi beberapa kelompok menggunakan GroupBy Function, kamu dapat mengakses setiap kelompok secara terpisah dengan menggunakan metode get_group().
Berikut ini adalah contoh kode untuk mengakses setiap kelompok menggunakan metode get_group():
# Membagi dataframe menjadi beberapa kelompok berdasarkan kolom "Jenis Kelamin"
grouped_df = df.groupby('Jenis Kelamin')
# Mengakses kelompok "Pria"
pria_group = grouped_df.get_group('Pria')
print(pria_group)
# Mengakses kelompok "Wanita"
wanita_group = grouped_df.get_group('Wanita')
print(wanita_group)
Di sini, kita membagi dataframe menjadi dua kelompok berdasarkan kolom “Jenis Kelamin”, kemudian mengakses setiap kelompok secara terpisah menggunakan metode get_group().
kamu dapat mengakses setiap kelompok secara terpisah untuk melakukan operasi yang diinginkan, seperti menghitung nilai agregat, mengubah tipe data, menghapus baris, dan lain-lain.
GroupBy Function sangat bermanfaat untuk memahami karakteristik data pada setiap kelompok secara terpisah dan membuat keputusan berdasarkan data yang tersedia.
GroupBy Function juga sangat bermanfaat dalam kasus-kasus dimana kamu ingin menghitung nilai agregat pada setiap kelompok berdasarkan beberapa kriteria tertentu.
Reset Index
Setelah melakukan agregasi menggunakan GroupBy Function, kamu mungkin ingin mengembalikan indeks dataframe ke bentuk aslinya, sehingga tidak lagi terbagi menjadi beberapa kelompok.
kamu dapat mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index().

Berikut ini adalah contoh kode untuk mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index():
# Membagi dataframe menjadi beberapa kelompok berdasarkan kolom "Jenis Kelamin"
grouped_df = df.groupby('Jenis Kelamin')
# Menghitung nilai agregat pada setiap kelompok menggunakan metode agg()
aggregates = grouped_df.agg(['mean', 'median', 'min', 'max'])
# Mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index()
reset_index_df = aggregates.reset_index()
print(reset_index_df)Di sini, kita membagi dataframe menjadi beberapa kelompok berdasarkan kolom “Jenis Kelamin”, kemudian menghitung nilai agregat pada setiap kelompok menggunakan metode agg().
Setelah itu, kita mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index().
Setelah mengembalikan indeks dataframe ke bentuk aslinya, dataframe tidak lagi terbagi menjadi beberapa kelompok, tetapi kembali menjadi dataframe yang terdiri dari baris dan kolom secara normal.
Metode reset_index() sangat bermanfaat untuk mengembalikan indeks dataframe ke bentuk aslinya setelah melakukan agregasi menggunakan GroupBy Function.
Dengan mengembalikan indeks dataframe ke bentuk aslinya, kamu dapat melakukan operasi dataframe secara normal, seperti mengubah tipe data, menambah dan menghapus baris dan kolom, dan lain-lain.
Reset Indek dengan Parameter Drop
Anda dapat menggunakan parameter drop pada metode reset_index() untuk menghapus kolom indeks yang sebelumnya digunakan sebagai kriteria pembagian dataframe menjadi beberapa kelompok. Berikut ini adalah contoh kode untuk menggunakan parameter drop pada metode reset_index():
# Mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index() dengan drop=True
reset_index_df = aggregates.reset_index(drop=True)
print(reset_index_df)kita mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index() dengan parameter drop bernilai True.
Setelah mengembalikan indeks dataframe ke bentuk aslinya dengan menghapus kolom indeks yang sebelumnya digunakan sebagai kriteria pembagian, dataframe tidak lagi terbagi menjadi beberapa kelompok, tetapi kembali menjadi dataframe yang terdiri dari baris dan kolom secara normal.
kamu juga dapat menggunakan parameter drop bernilai False untuk mengembalikan indeks dataframe ke bentuk aslinya, tetapi tetap menyimpan kolom indeks yang sebelumnya digunakan sebagai kriteria pembagian.
# Mengembalikan indeks dataframe ke bentuk aslinya menggunakan metode reset_index() dengan drop=False
reset_index_df = aggregates.reset_index(drop=False)
print(reset_index_df)Mengubah Nama Kolom pada DataFrame
Ada beberapa cara yang dapat dilakukan untuk mengubah nama kolom dataframe pada Python, di antaranya adalah sebagai berikut:
-
Menggunakan operator assignment (
=)
kamu dapat mengubah nama kolom dataframe menggunakan operator assignment (=) dengan cara memberikan nama baru pada kolom tersebut.
Berikut ini adalah contoh kode untuk mengubah nama kolom dataframe menggunakan operator assignment:
# Mengubah nama kolom "Usia" menjadi "Age" menggunakan operator assignment
df.columns.values[1] = 'Age'
print(df)Di sini, kita mengubah nama kolom “Usia” menjadi “Age” menggunakan operator assignment. Setelah mengubah nama kolom “Usia”, dataframe akan terlihat seperti berikut:
Nama Age Gaji Pendidikan
0 Andi 21 1000 S1
1 Budi 22 2000 S1
2 Caca 23 3000 S2
3 Deni 24 4000 S2
4 Euis 25 5000 S3
-
Menggunakan metode
rename()
kamu dapat mengubah nama kolom dataframe menggunakan metode rename(). Berikut ini adalah contoh kode untuk mengubah nama kolom dataframe menggunakan metode rename():
# Mengubah nama kolom "Usia" menjadi "Age" menggunakan metode rename()
df = df.rename(columns={'Usia': 'Age'})
print(df)-
Menggunakan metode
set_axis()
kamu dapat mengubah nama kolom dataframe menggunakan metode set_axis(). Berikut ini adalah contoh kode untuk mengubah nama kolom dataframe menggunakan metode set_axis():
# Mengubah nama kolom "Usia" menjadi "Age" menggunakan metode set_axis()
df.set_axis(['Nama', 'Age', 'Gaji', 'Pendidikan'], axis='columns', inplace=True)
print(df)-
Menggunakan metode
update()
kamu dapat mengubah nama kolom dataframe menggunakan metode update(). Berikut ini adalah contoh kode untuk mengubah nama kolom dataframe menggunakan metode update():
# Mengubah nama kolom "Usia" menjadi "Age" menggunakan metode update()
df.columns.update(['Nama', 'Age', 'Gaji', 'Pendidikan'])
print(df)-
Menggunakan metode
columns.map()
kamu dapat mengubah nama kolom dataframe menggunakan metode columns.map(). Berikut ini adalah contoh kode untuk mengubah nama kolom dataframe menggunakan metode columns.map():
# Mengubah nama kolom "Usia" menjadi "Age" menggunakan metode columns.map()
df.columns = df.columns.map({'Usia': 'Age'})
print(df)-
Menggunakan metode
columns.set_names()
kamu dapat mengubah nama kolom dataframe menggunakan metode columns.set_names(). Berikut ini adalah contoh kode untuk mengubah nama kolom dataframe menggunakan metode columns.set_names():
# Mengubah nama kolom "Usia" menjadi "Age" menggunakan metode columns.set_names()
df.columns.set_names(['Nama', 'Age', 'Gaji', 'Pendidikan'], inplace=True)
print(df)PivotTable DataFrame
Pivot table adalah sebuah fitur yang disediakan oleh pandas untuk memudahkan Anda dalam mengelompokkan dataframe berdasarkan kolom tertentu, menghitung nilai statistik dari data yang telah dikelompokkan, dan menampilkan hasilnya dalam bentuk tabel.
Pivot table bisa sangat bermanfaat jika Anda ingin mengelompokkan dataframe berdasarkan beberapa kriteria dan melakukan perhitungan terhadap data yang telah dikelompokkan tersebut.
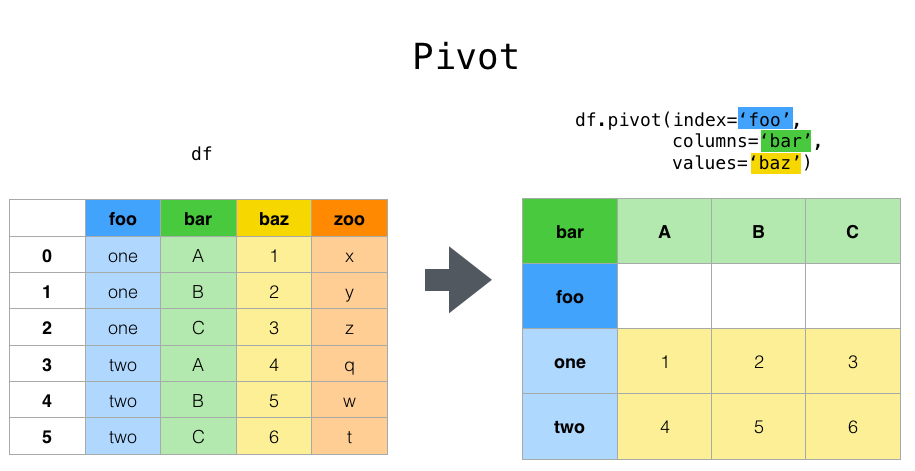
Untuk menggunakan pivot table pada dataframe, Anda bisa menggunakan metode pivot_table(). Berikut ini adalah contoh sederhana menggunakan metode pivot_table() pada dataframe:
import pandas as pd
# Membuat dataframe sederhana
df = pd.DataFrame({'Nama': ['Andi', 'Budi', 'Caca', 'Deni', 'Euis'],
'Usia': [21, 22, 23, 24, 25],
'Gaji': [1000, 2000, 3000, 4000, 5000],
'Pendidikan': ['S1', 'S1', 'S2', 'S2', 'S3']})
# Membuat pivot table dari dataframe df
pivot = df.pivot_table(index='Usia', columns='Pendidikan', values='Gaji', aggfunc='mean')
print(pivot)Di sini, kita membuat pivot table dari dataframe df dengan mengelompokkan data berdasarkan kolom Usia dan Pendidikan, dan menghitung rata-rata dari kolom Gaji menggunakan metode mean().
Hasilnya akan terlihat seperti berikut:
Pendidikan S1 S2 S3
Usia
21 1000.0 NaN NaN
22 2000.0 NaN NaN
23 NaN 3000.0 NaN
24 NaN 4000.0 NaN
25 NaN NaN 5000.
# Membuat pivot table dari dataframe df dengan mengelompokkan data berdasarkan kolom Pendidikan dan Usia
pivot = df.pivot_table(index=['Pendidikan', 'Usia'], columns='Nama', values='Gaji', aggfunc='mean')
print(pivot)
Nama Andi Budi Caca Deni Euis
Pendidikan Usia
S1 21 1000.0 NaN NaN NaN NaN
22 NaN 2000.0 NaN NaN NaN
S2 23 NaN NaN 3000.0 NaN NaN
24 NaN NaN NaN 4000.0 NaN
S3 25 NaN NaN NaN NaN 5000.0Pivot Table untuk Data Aggregation
Pivot table juga dapat digunakan untuk melakukan data aggregation, yaitu proses menghitung statistik dasar seperti jumlah, rata-rata, median, dan sebagainya dari sebuah dataframe.
Berikut ini adalah contoh kode yang menggunakan pivot table untuk melakukan data aggregation:
import pandas as pd
# Membuat dataframe sederhana
df = pd.DataFrame({'Nama': ['Andi', 'Budi', 'Caca', 'Deni', 'Euis'],
'Usia': [21, 22, 23, 24, 25],
'Gaji': [1000, 2000, 3000, 4000, 5000],
'Pendidikan': ['S1', 'S1', 'S2', 'S2', 'S3']})
# Membuat pivot table dari dataframe df dengan mengelompokkan data berdasarkan kolom Usia
pivot = df.pivot_table(index='Usia', values='Gaji', aggfunc=['mean', 'median', 'min', 'max'])
print(pivot)
Di sini, kita membuat pivot table dari dataframe df dengan mengelompokkan data berdasarkan kolom Usia, dan menghitung rata-rata, median, nilai minimum, dan nilai maksimum dari kolom Gaji menggunakan metode mean(), median(), min(), dan max().
Hasilnya akan terlihat seperti berikut:
mean median min max
Usia
21 1000.0 1000.0 1000.0 1000.0
22 2000.0 2000.0 2000.0 2000.0
23 3000.0 3000.0 3000.0 3000.0
24 4000.0 4000.0 4000.0 4000.0
25 5000.0 5000.0 5000.0 5000.0
Selain itu, kamu juga bisa mengelompokkan data menggunakan fungsi groupby().
Fungsi groupby() mirip dengan pivot table, tetapi lebih fleksibel karena kamu bisa menentukan sendiri bagaimana data harus dikelompokkan dan diolah.
atau dengan menentukan agregat pada masing-masing kolom seperti pada kode berikut
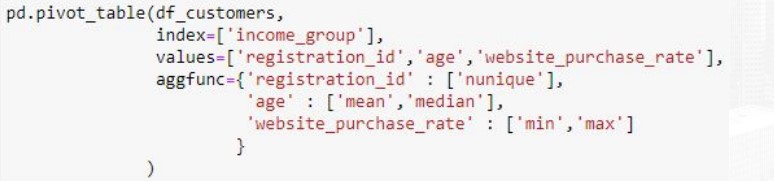
Demikianlah DataFrame Aggregation, semoga bermanfaat.